
Research Projects
- Spark Scheduling
With the explosion of the dataset in big data area, high-performance and scalable in-memory frameworks become the future trending for data-intensive processing in both industry and academia. Spark has revealed the potential to become the new standard distributed framework due to its favorable efficiency and expandability. Thus, how to keep maximizing the computing efficiency is one of the primary concerns in Spark. We found that current Spark implementation lack of task scheduling mechanism which does not yield the optimal task arrangement unnecessarily extending the makespan of stages. To address this issue, we propose a simple Spark scheduler which can effectively reduce the makespan of Spark application by leveraging the task information in multiple parallel stages.
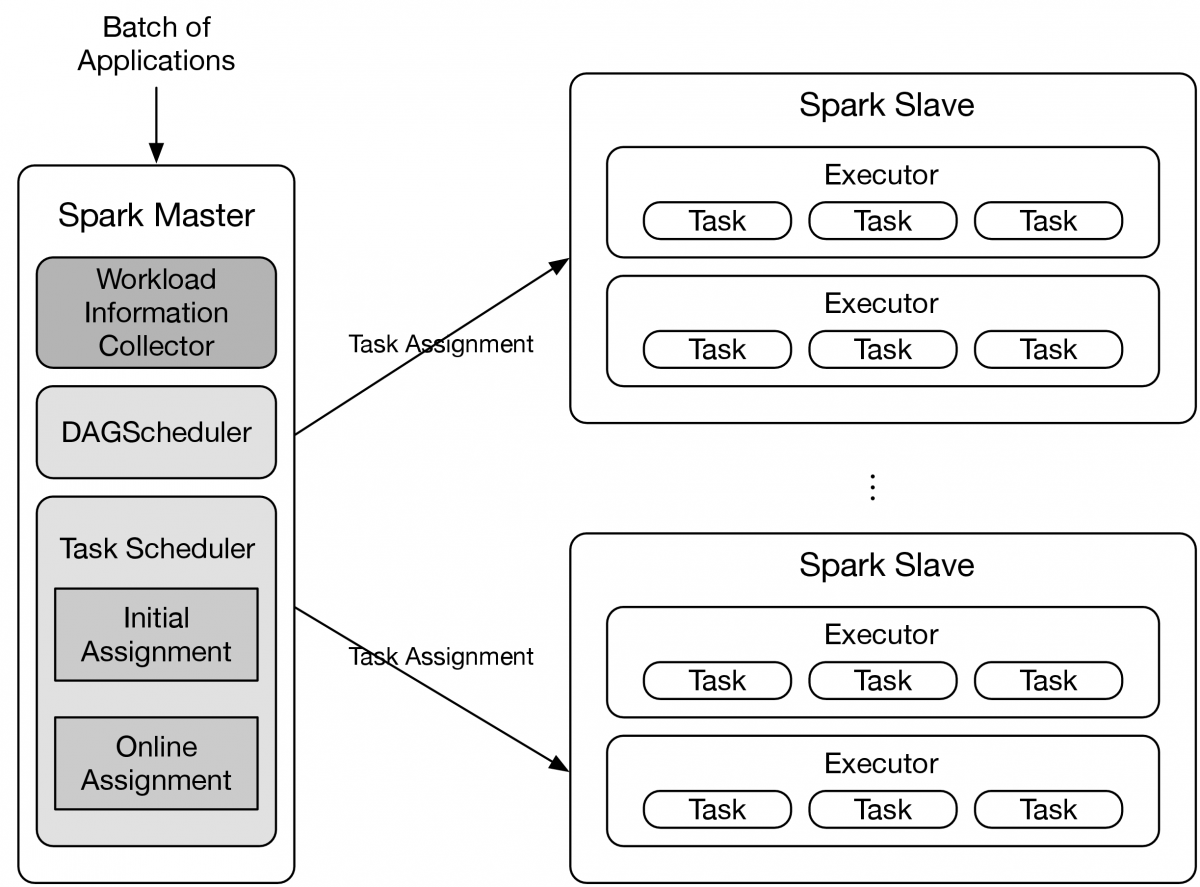
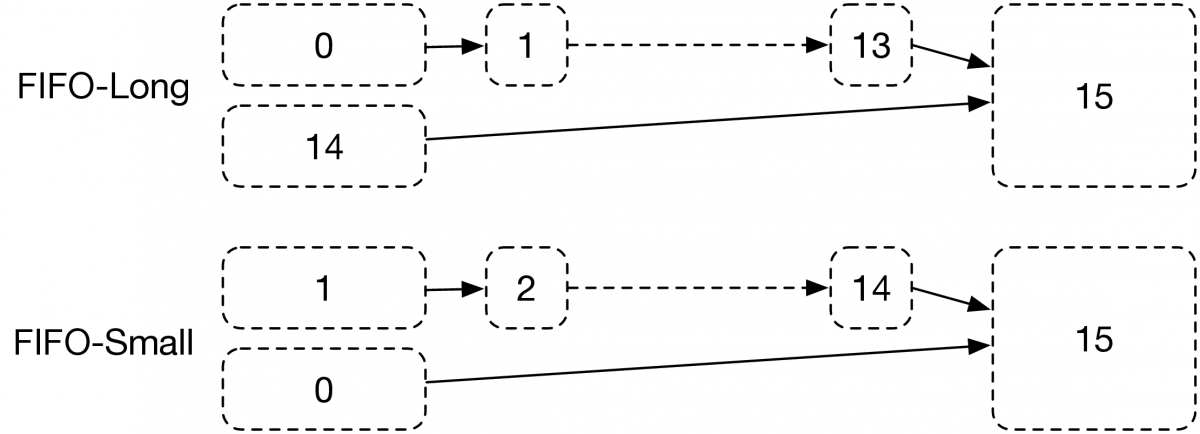
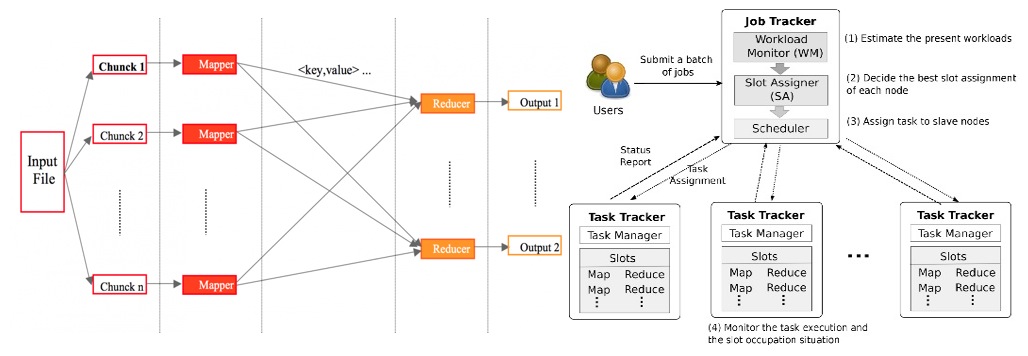
- MapReduce / Hadoop Scheduling
The MapReduce framework and its open source implementation Hadoop have become the defacto platform for scalable on large data sets in recent years. One of the primary concerns in Hadoop is how to optimize the performance of MapReduce jobs, i.e., average job response times and job makespans. In this project, new schedulers and resource management schemes for MapReduce/Hadoop distributed systems are designed to improve the performance in terms of average job response times and job makespans. The proposed schedulers have been implemented in the Apache Hadoop and evaluated using a set of real representative data processing applications. We design and implement a new Hadoop scheduler, which leverages the knowledge of workload patterns to improve the average job response time by dynamically tuning the resource shares among users and the scheduling algorithms for each user; We also design and implement a new scheme which uses slot ratio between map and reduce tasks as a tunable knob for effectively reducing the makespan of a batch of MapReduce jobs; We investigate the existing Hadoop scheduling policies and the classic heuristics for resource constraint project scheduling in Next Generation MapReduce (Yarn) systems and develop a new resource manage scheme to maximize the resource utilization of these NGM systems. [IM'13] [Cloud'13][TCC'14][Cloud'14]
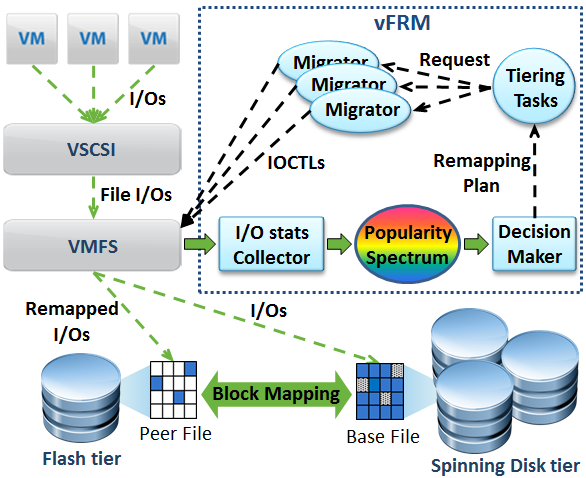
- vFRM: Flash Resource Manager in VMware ESX Server
One popular approach of leveraging Flash technology in the virtual machine environment today is using it as a secondary-level host-side cache. Although this approach delivers I/O acceleration for a single VM workload, it might not be able to fully exploit the outstanding performance of Flash and justify the high cost-per-GB of Flash resources. In this paper, we design VMware Flash Resource Manager (vFRM), which aims to maximize the utilization of Flash resources with minimal CPU, memory and I/O cost for managing and operating Flash. It borrows the ideas of heating and cooling from thermodynamics to identify the data blocks that benefit most from being put on Flash, and lazily and asynchronously migrates the data blocks between Flash and spinning disks. [NOMS'14]
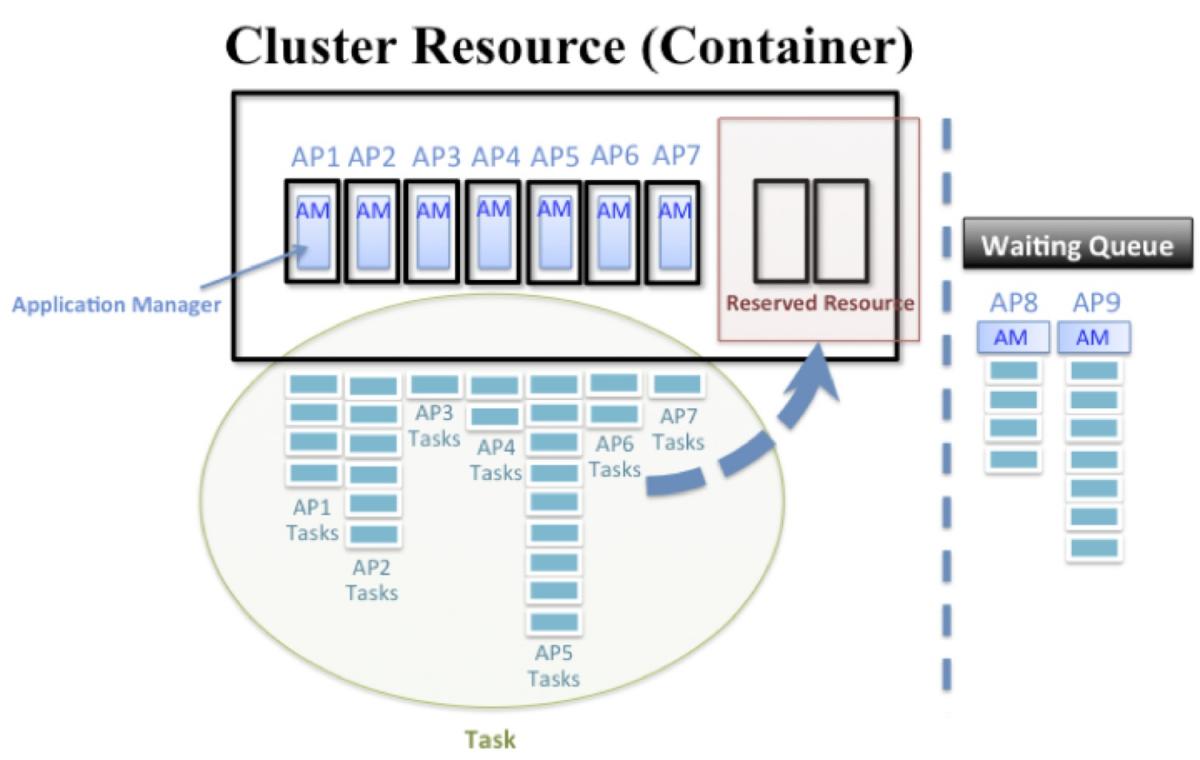
- Admission Control Mechanism to the Fair Scheduling Policy of the MapReduce 2.0
The project I am doing is about the admission control mechanism to the fair scheduling policy of the MapReduce 2.0 (MRv2). In general, it is common that many systems or frameworks deploy the fair scheduling which can equally distributed the resource to process their applications efficiently. My project is to focus on the problem while the resource demand of submitting applications' is over the capability one cluster can provide, especially in a small or medium Hadoop system. All the resource of the cluster will assign to the controller of each application (Application Master), and there is no extra resource left to process the tasks among each application. This will happen to a suspension in the Hadoop system. The promising way is to set up the resource check-point when submitting an application as well as reserve a feasible resource dynamically according to the utilization from the system.
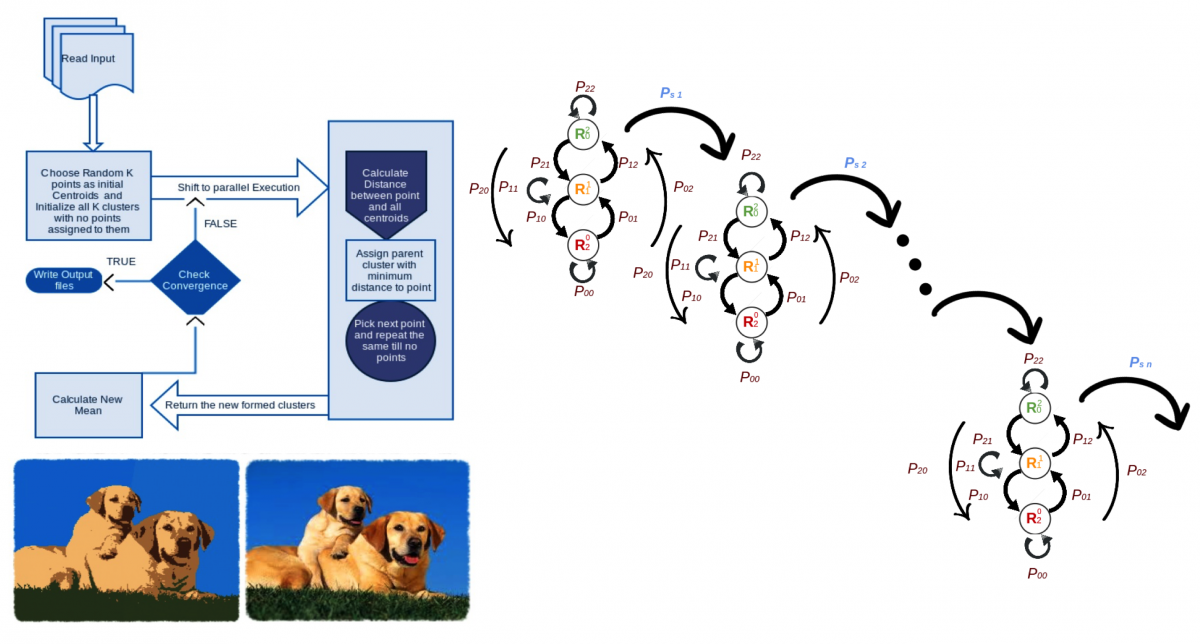
- Predicting the Performance of Algorithms running on Heterogeneous Computing Platforms
We are investigating various highly used algorithms including Clustering, Computed Tomography (CT) Image Reconstruction, Gaussian Mixture Models, Latent Dirichlet Allocation etc to predict the expected improvement in performance of these algorithms on heterogeneous platform of CPU, GPU and platforms using multiple threads and processors. By successfully capturing the characteristics of heterogeneous processing elements, our model predicts individual processing times for each stage (e.g., image weighting, filtering and reconstruction) in CT image reconstruction. Specifically, we built an underlying Markov model to predict the performance using low level thread activity for its execution. The states in which one thread can exists at any given time is either active or passive. The model estimates probabilities for jumping between these two states or staying in the same state. These estimates the total time that stage may take. We further extend our model to support the prediction of an application running with a large number of threads. By comparing the predicted results with the actual ones, we found that our Markov-based prediction models are able to accurately estimate the execution times for each stage as well as the entire CT image reconstruction process. In the future we plan to apply our performance prediction to more sophisticated machine learning algorithms including Gaussian Mixture Models and Latent Dirichlet Allocation. We derived the K-means Clustering output with algorithm running on heterogeneous Computing Platforms using CUDA, MPI and OpenMP and currentlt working on building a Prediction Model for it.
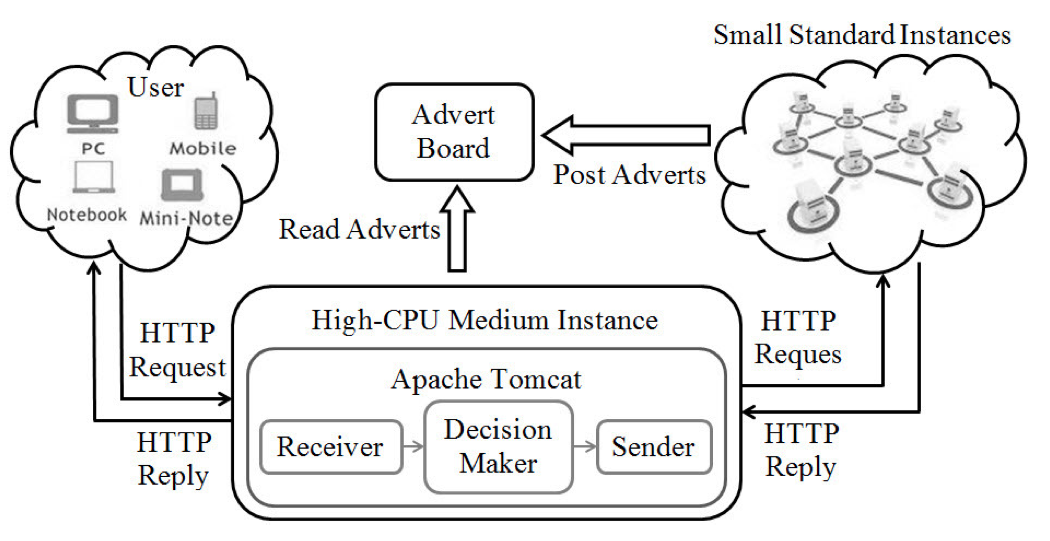
- ARA: Adaptive Resource Allocation for Cloud Computing Environments under Bursty Workloads
Cloud computing nowadays becomes quite popular among a community of cloud users by offering a variety of resources. However, burstiness in user demands often dramatically degrades the application performance. In order to satisfy peak user demands and meet Service Level Agreement (SLA), efficient resource allocation schemes are highly demanded in the cloud. However, we find that conventional load balancers unfortunately neglect cases of bursty arrivals and thus experience significant performance degradation. Motivated by this problem, we propose new burstiness-aware algorithms to balance bursty workloads across all computing sites, and thus to improve overall system performance. We present a smart load balancer, which leverages the knowledge of burstiness to predict the changes in user demands and on-the-fly shifts between the schemes that are “greedy” (i.e., always select the best site) and “random” (i.e., randomly select one) based on the predicted information. This work is currently supported by AWS (Amazon Web Services) in Education Research Grant. [ICC'11] [IPCCC'11] [ICC'12] [SIMPAT'14]
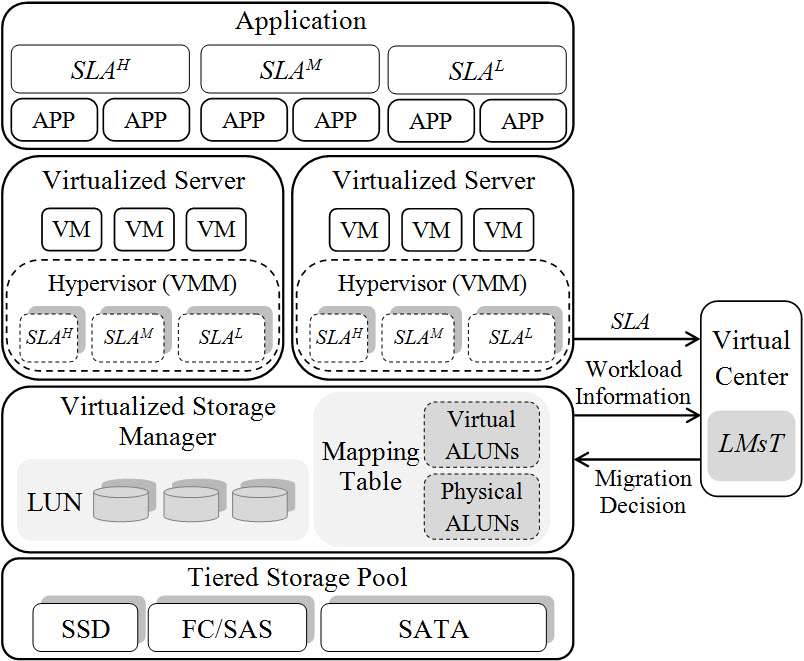
- Reducing SLA Violations via Live Data Migration in Multi-tiered Storage Systems
Large-scaled and diverse data sets are raising new big challenges of storage, process, and query. Tiered storage architectures combining solid-state drives (SSDs) with hard disk drives (HDDs), become attractive in enterprise data centers for achieving high performance and large capacity simultaneously. However, how to best use these storage resources and efficiently manage massive data for providing high quality of service (QoS) is still a core and difficult problem. In this paper, we present a new approach for automated data movement in multi-tiered storage systems, which lively migrates the data across different tiers, aiming to support multiple SLAs for applications with dynamic workloads at the minimal cost. [IWCA'14]
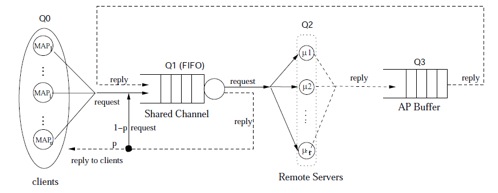
- DAT: Access Point Scheduler
A new packet scheduling algorithm for access points in a crowded 802.11 WLAN is designed in this project. The goal is to improve the performance of efficiency (measured by packet response time or throughput) and fairness which often conflict with each other. A solution is designed to aggregates both metrics and leverages the balance between them. The basic idea is to let the AP allocate different time windows for serving each client. According to the observed traffic, the algorithm dynamically shifts the weight between efficiency and fairness and strikes to improve the preferred metric without excessively degrading the other one. A valid queuing model is developed to evaluate the new algorithm’s performance. Using trace-driven simulations, we show that our algorithm successfully balances the trade off between the efficiency and the fairness in a busy WLAN. [IPCCC'13]
- Performance Analysis on Workloads and Log Blocks Assignments in FTL
Hybrid FTL schemes are using sequential log blocks (SLB) and random log blocks (RLB) to reveal sequential write steams from mixed random and sequential write streams. Due to the erase-before-write limitation, sequential writes help to reduce lots of whole-block-erasing time cost. We build a mathmatic model to indicate the performance changing trend according to the workloads characteristics (such as sequential random ratio (SRR), sequential stream length (SSL)) and the assignment strategy of sequential/random log blocks. We conduct both synthetical and real traces on different log blocks assignments and indicate the optimized assignments. In future, an adaptive assignment technique will be developed an adaptive assignment technique based on our mathmatic model.
